
Flash Attention in a Flash: https://arxiv.org/abs/2205.14135
Table of Contents
Open Table of Contents
Jumping right In
Here, we will quickly go through the widely used Flash Attention mechanism [1] and understand why it’s such incredible algorithm for performing attention, and doing so very quickly.
TL;DR: It restructures how it computes the softmax for the attention matrix that is very mindful of the performance characteristics of modern GPU HBM (high bandwidth memory) and shared memory. It avoids materializing the attention matrix, which is a very large matrix, and never reads or writes to the HBM. This is achieved by using an online softmax trick that allows for incremental evaluation of the softmax without realizing all the inputs to the softmax normalization.
First, consider the fairly standard PyTorch implementation for multi-head causal attention:
class CausalAttention(nn.Module):
# ...(init method)...
def forward(self, x: torch.Tensor):
bsz, seqlen, dim = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.reshape(bsz, seqlen, self.num_heads_q, self.head_dim)
xk = xk.reshape(bsz, seqlen, self.num_heads_kv, self.head_dim)
xv = xv.reshape(bsz, seqlen, self.num_heads_kv, self.head_dim)
xq = xq.transpose(1, 2) # (bsz, num_heads_q, seqlen, head_dim)
xk = xk.transpose(1, 2) # (bsz, num_heads_kv, seqlen, head_dim)
xv = xv.transpose(1, 2) # (bsz, num_heads_kv, seqlen, head_dim)
# Flash Attention modifies the following lines
attn = (xq @ xk.transpose(-2, -1)) / (self.head_dim**0.5)
attn = attn + self.mask[:, :, :seqlen, :seqlen]
attn = F.softmax(attn, dim=-1)
attn = self.attn_dropout(attn)
out = attn @ xv
# restore seqlen into batch dim and concatenate heads
out = out.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
out = self.wo(out)Now, focus your attention on the highlighted lines above, and consider how data moves in and out of the high bandwidth memory (HBM) in a typical multi-head attention operation:
Require: Matrices in HBM.
- Load by blocks from HBM, compute , write to HBM.
- Read from HBM, compute , write to HBM.
- Load and by blocks from HBM, compute , write to HBM.
- Return .
What makes the above steps inefficient is that the attention matrix and is materialized fully at each step, and reading/writing this huge matrix to HBM is very expensive. This is where all the queries and keys interact, and for each head, for each batch element, we’re getting a matrix of attention, which is a million numbers, even for a single head, at a single batch index, like so.So basically this is a ton of memory, and this is never materialized.
Flash Attention comes into play by modifying these steps, implementing them very quickly. But how does it do that?
Flash Attention is a Kernel Fusion Operation
Well, Flash Attention is a kernel fusion operation. So you see here, on the right side of the diagram, they’re showing PyTorch and you have these five operations. And instead of those, we are fusing them into a single fused kernel of Flash Attention.
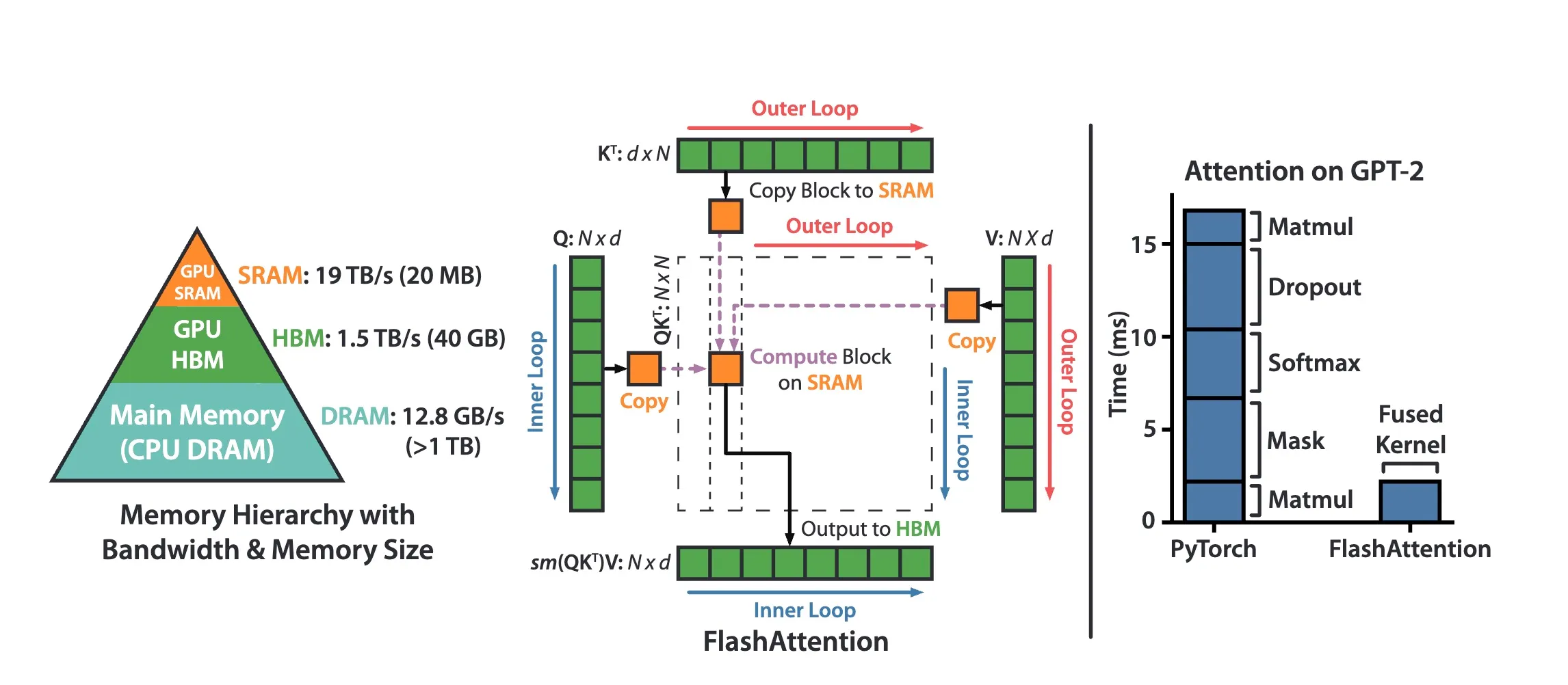
So it’s a kernel fusion algorithm, but it’s a kernel fusion that torch compile cannot find. And the reason that it cannot find it is that it requires an algorithmic rewrite of how attention is actually implemented here in this case. And what’s remarkable about it is that Flash Attention, actually, if you just count number of flops, Flash Attention does more flops than this attention here.
But Flash Attention is actually significantly faster. In fact, they cite 7.6 times faster, potentially. And that’s because it is very mindful of the memory hierarchy, as I mentioned. And so it’s very mindful about what’s in high bandwidth memory, what’s in the shared memory, and it is very careful without orchestras to computation, such that we have fewer reads and writes to the high bandwidth memory. And so even though we’re doing more flops, the expensive part is they’re load and store into HPM, and that’s what they avoid.
Online Softmax “trick”
How does Flash Attention avoid materializing the attention matrix?
The way that this is achieved is with the online softmax trick, which was proposed previously [2]. The online softmax trick from that paper shows how you can incrementally evaluate a softmax without having to sort of realize all of the inputs to the softmax of the normalization. And remarkably, it came out of Nvidia really early 2018. So this is four years before Flash attention. And this paper says that,
We propose a way to compute the classical softmax with fewer memory accesses and hypothesize that this reduction in memory accesses should improve softmax performance on actual hardware.
And so they are extremely correct in this hypothesis.
Let’s see how:
Safe softmax with online normalizer calculation
- (Keep track of maximum value)
- (normalization term)
- for do
- (update maximum value)
- (update normalization term)
- end for
The key insight is in the normalizer update is calculated. When a new maximum is encountered, the term scales down the previous normalizer sum. This is equivalent to subtracting from all previous exponents, which maintains the relative scales without requiring the full sum. This is the key to the online softmax:
At a given step , the normalizer is updated as follows:
In PyTorch:
import torch
def online_softmax_iterative(x: torch.Tensor, dim: int = -1):
"""Compute softmax over a specified dimension, online.
Args:
x (torch.Tensor): Input tensor.
dim (int, optional): Dimension to apply softmax over. Defaults to -1.
Returns:
torch.Tensor: Softmax output.
"""
# Move dimension to be reduced to the end
x = x.transpose(dim, -1)
# Initialize intermediate variables
m = torch.full_like(x[..., :1], float("-inf")) # (..., 1)
d = torch.zeros_like(x[..., :1]) # (..., 1)
y = torch.zeros_like(x) # (same shape as x)
for j in range(x.size(-1)):
x_j = x[..., j : j + 1] # get current value (keep dim) (..., 1)
# Update maximum
m_new = torch.maximum(m, x_j) # (..., 1)
# Update normalizer
d = torch.exp(m - m_new) * d + torch.exp(x_j - m_new) # (..., 1)
# Store new maximum
m = m_new
for j in range(x.size(-1)):
x_j = x[..., j : j + 1]
y[..., j : j + 1] = torch.exp(x_j - m) / d
# Restore original shape
return y.transpose(dim, -1)
# Example usage
x = torch.randn(3, 4, 5)
result = online_softmax_iterative(x, dim=1)
print(result.shape) # Should be (3, 4, 5)
# Verify against PyTorch's softmax
torch_softmax = torch.nn.functional.softmax(x, dim=1)
print(torch.allclose(result, torch_softmax, atol=1e-6)) # Should be TrueAlgorithm 1: FlashAttention
Now, let’s see how the online softmax trick is used in the Flash Attention algorithm. The following is a high-level description of the Flash Attention algorithm (note that in their notation, they use instead of .)
Require: Matrices in HBM, on-chip SRAM of size .
- Set block sizes , .
- Initialize , , in HBM.
- Divide into blocks of size each, and divide in to blocks and , of size each.
- Divide into blocks of size each, divide into blocks of size each, divide into blocks of size each.
- for do
- Load from HBM to on-chip SRAM.
- for do
- Load from HBM to on-chip SRAM.
- On chip, compute .
- On chip, compute , (pointwise), .
- On chip, compute , .
- Write to HBM.
- Write , to HBM.
- end for
- end for
- Return .
And in PyTorch, this is how you would implement Flash Attention (educational purposes only):
import math
import torch
import torch.nn.functional as F
def flash_attention(Q, K, V, M):
N, d = Q.shape
# Step 1: Set block sizes
Bc = int(M / (4 * d))
Br = min(int(M / (4 * d)), d)
# Step 2: Initialize
O = torch.zeros(N, d)
l = torch.zeros(N)
m = torch.full((N,), -float("inf"))
# Step 3 & 4: Divide matrices into blocks
Tr = int(math.ceil(N / Br))
Tc = int(math.ceil(N / Bc))
for j in range(Tc):
# Step 6: Load Kj, Vj
Kj = K[j * Bc : (j + 1) * Bc, :] # [Bc, d]
Vj = V[j * Bc : (j + 1) * Bc, :] # [Bc, d]
for i in range(Tr):
# Step 8: Load Qi, Oi, li, mi (simulated as slicing)
Qi = Q[i * Br : (i + 1) * Br, :] # [Br, d]
Oi = O[i * Br : (i + 1) * Br, :] # [Br, d]
li = l[i * Br : (i + 1) * Br] # [Br]
mi = m[i * Br : (i + 1) * Br] # [Br]
# Step 9: Compute Sij
Sij = torch.matmul(Qi, Kj.T)
# Step 10: Compute intermediate values
mij_tilde = torch.max(Sij, dim=1).values
Pij_tilde = torch.exp(Sij - mij_tilde[:, None])
lij_tilde = torch.sum(Pij_tilde, dim=1)
# Step 11: Update mi and li
mi_new = torch.maximum(mi, mij_tilde)
li_new = (
torch.exp(mi - mi_new) * li + torch.exp(mij_tilde - mi_new) * lij_tilde
)
# Step 12: Update Oi
Oi_new = torch.diag(1 / li_new) @ (
torch.diag(li) @ torch.exp(mi - mi_new)[:, None] * Oi
+ torch.exp(mij_tilde - mi_new)[:, None] * (Pij_tilde @ Vj)
)
# Step 13: Write back to main memory (simulated as updating slices)
O[i * Br : (i + 1) * Br, :] = Oi_new
l[i * Br : (i + 1) * Br] = li_new
m[i * Br : (i + 1) * Br] = mi_new
return O
def standard_attention(Q, K, V):
# Compute attention scores
scores = torch.matmul(Q, K.transpose(-2, -1))
# Apply softmax to get attention weights
attn_weights = F.softmax(scores, dim=-1)
return torch.matmul(attn_weights, V)
# Example usage
N, d = 1024, 64 # Example dimensions
M = 8192 # Example on-chip memory size
Q = torch.randn(N, d)
K = torch.randn(N, d)
V = torch.randn(N, d)
# Compute attention using both methods
flash_result = flash_attention(Q, K, V, M)
standard_result = standard_attention(Q, K, V)
# Compare results
max_diff = torch.max(torch.abs(flash_result - standard_result))
mean_diff = torch.mean(torch.abs(flash_result - standard_result))
relative_diff = torch.norm(flash_result - standard_result) / torch.norm(standard_result)
print(f"Max absolute difference: {max_diff:.6f}")
print(f"Mean absolute difference: {mean_diff:.6f}")
print(f"Relative difference: {relative_diff:.6f}")
# Check if results are close
tolerance = 1e-5
is_close = torch.allclose(flash_result, standard_result, rtol=tolerance, atol=tolerance)
print(f"Results are close (tolerance {tolerance}): {is_close}")Flash Attention Visualized
+-------------------+ +-------------------+
| Input | | Memory Usage |
| Matrices (HBM) | | |
| +---+---+---+ | | +-------------+ |
| | Q | K | V | | | | On-Chip SRAM| |
| +---+---+---+ | | | (Size M) | |
+-------------------+ | +-------------+ |
| | | |
v | v |
+-------------------+ | +-------------+ |
| Block Division | | | Block Sizes | |
| +---+---+---+---+ | | | Bc and Br | |
| |Q1 |Q2 |...|QTr| | | +-------------+ |
| +---+---+---+---+ | +-------------------+
| +---+---+---+---+ | |
| |K1 |K2 |...|KTc| | |
| +---+---+---+---+ | |
| +---+---+---+---+ | |
| |V1 |V2 |...|VTc| | |
| +---+---+---+---+ | |
+-------------------+ |
| |
v v
+--------------------------------------------------------+
| Processing Loop |
| +----------------+ +------------------------+ |
| | For each K,V | ---> | For each Q block | |
| | block | | 1. Load Q,O,l,m | |
| | | | 2. Compute S | |
| | Load to SRAM | | 3. Update O,l,m | |
| +----------------+ | 4. Write back to HBM | |
| +------------------------+ |
+--------------------------------------------------------+
|
v
+-------------------+
| Output (HBM) |
| +-------------+ |
| | O | |
| +-------------+ |
+-------------------+