Introduction: A New Chapter in Scientific Discovery
In the final day of 12 Days of OpenAI, OpenAI unveiled o3, the latest iteration of their revolutionary o-series models. While its immediate achievements—mastering competitive programming challenges and advanced mathematics—are impressive, the deeper implications for scientific discovery are profound. We likely stand at a threshold where artificial intelligence is evolving from a sophisticated calculator into something unprecedented: an active participant in the scientific process itself.
o3’s announcement - capabilities suggest a fundamental shift in how we approach scientific discovery
On the Future of Knowledge Work
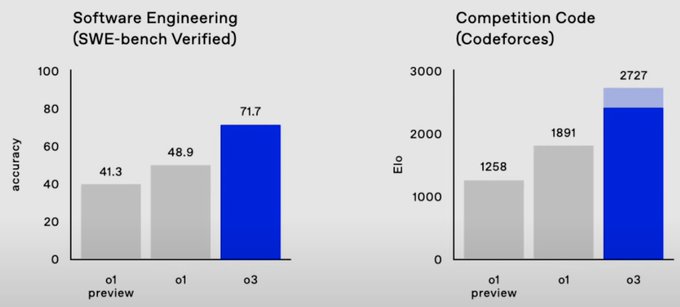
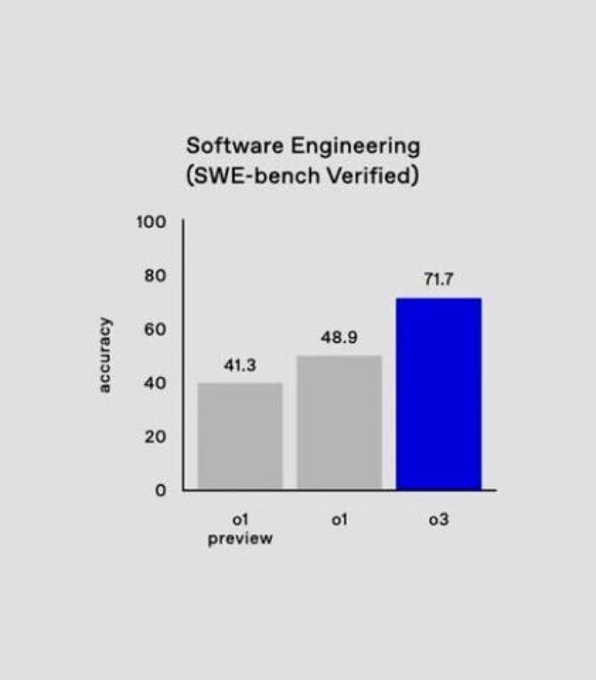
Consider the presented benchmarks: o3 scores better than 99.8% of competitive programmers on Codeforces, achieving a rating of 2727—equivalent to the world’s 175th best human coder. More remarkably, it demonstrates the ability to reason through complex mathematical proofs, design experiments, and evaluate its own performance. These capabilities hint at something revolutionary: the potential for AI to participate in the full cycle of scientific inquiry, from hypothesis generation to experimental design and analysis.
While there has been a wild fury of opinions and declarations regarding the o3 announcement, I think the points related to this article are nicely captured in these posts on x:
o3 is very performant. More importantly, progress from o1 to o3 was only three months, which shows how fast progress will be in the new paradigm of RL on chain of thought to scale inference compute. Way faster than pretraining paradigm of new model every 1-2 years
We announced @OpenAI o1 just 3 months ago. Today, we announced o3. We have every reason to believe this trajectory will continue.
Practice working with AI. Human+AI will be superior to human or AI alone for the foreseeable future. Those who can work most effectively with AI will be the most highly valued.
serious question what should a CS student (or any knowledge worker for that matter) do at this point? even if the model is $2000/month, it’s still cheaper than a graduate employee what’s the plan now?
The rate of progress in AI capabilities raises fundamental questions about the future of knowledge work and scientific discovery more broadly.
The notable aspects are:
- Raw performance
- Rate of progress
- What do “the rest of us” do now?
Noam’s response to the second tweet is particularly interesting suggests, for the time being at least, that the future of scientific discovery may lie not in competition between humans and AI, but in their collaboration. As we dig deeper into this topic, we’ll explore how this symbiosis might reshape the landscape of scientific research and what it means for the future of human knowledge and innovation.
Three Critical Questions
This release raises three fundamental questions that will shape the future of scientific research:
-
Can AI truly participate in scientific discovery? While o3 excels at mathematical reasoning, science demands more than logical deduction—it requires empirical observation, physical experimentation, and the recognition of serendipitous discoveries.
-
How will the human-AI relationship evolve? As AI systems become more capable, will they remain tools, become competitors, or emerge as true collaborators in scientific inquiry?
-
What are the implications for scientific methodology? The scientific method has remained relatively unchanged since the Enlightenment. Could AI-enabled discovery force us to rethink this fundamental process?
This article explores these questions through multiple lenses: historical context, current capabilities, fundamental limitations, and future possibilities. We’ll examine how o3 and its successors might reshape scientific discovery while considering the essential role human insight and physical experimentation must continue to play.
The Evolution of Scientific Tools: From Microscopes to Machine Learning
The Transformative Power of New Tools
The relationship between technology and science has always been symbiotic, each driving the other forward in a continuous cycle of innovation and discovery. From the telescope revealing the mysteries of our cosmos to DNA sequencing unlocking the secrets of life, technological breakthroughs have consistently transformed our ability to observe and understand the natural world. Throughout history, these tools have acted as extensions of human perception and analysis, enabling scientists to explore realms previously beyond our reach.
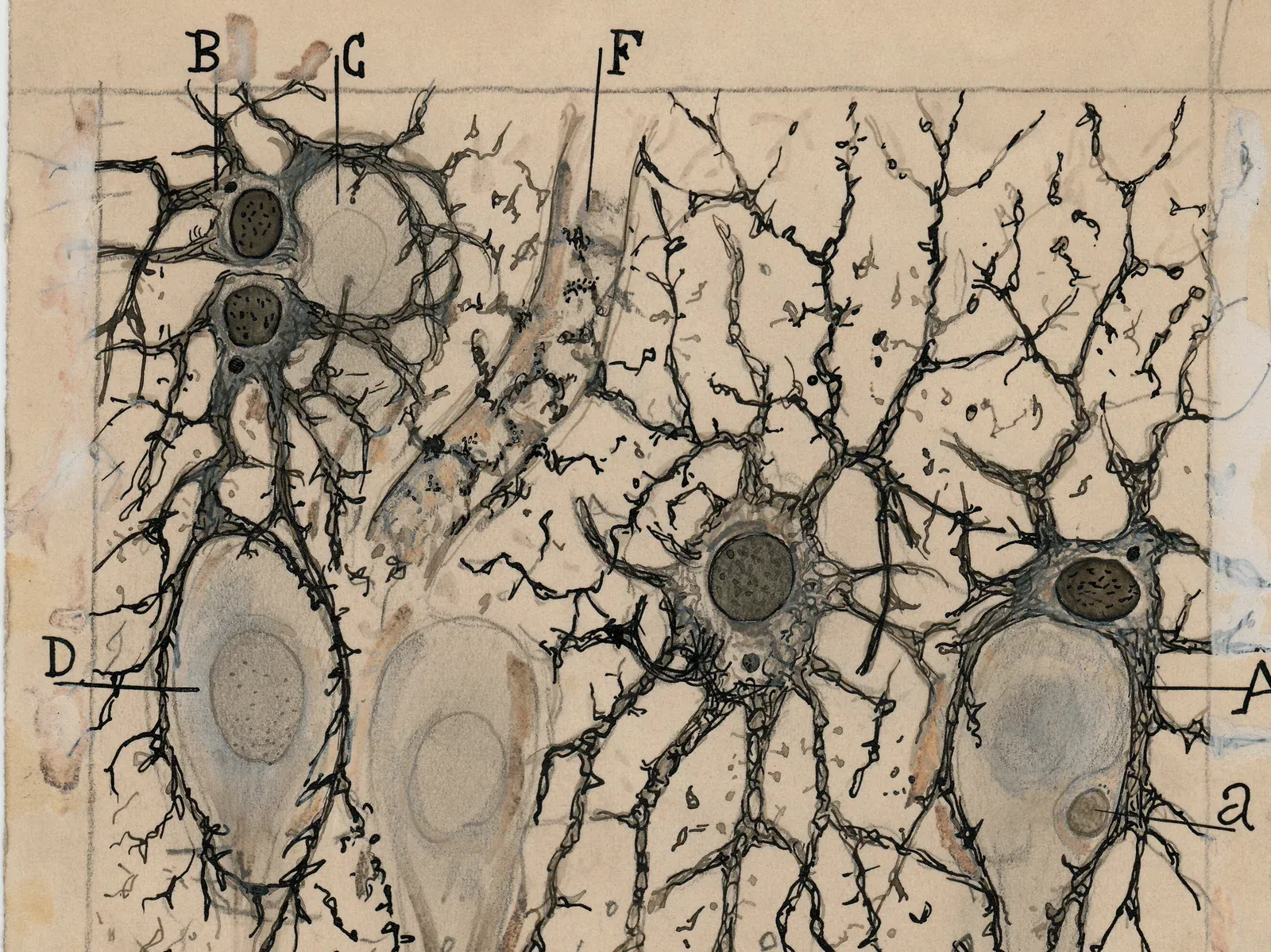
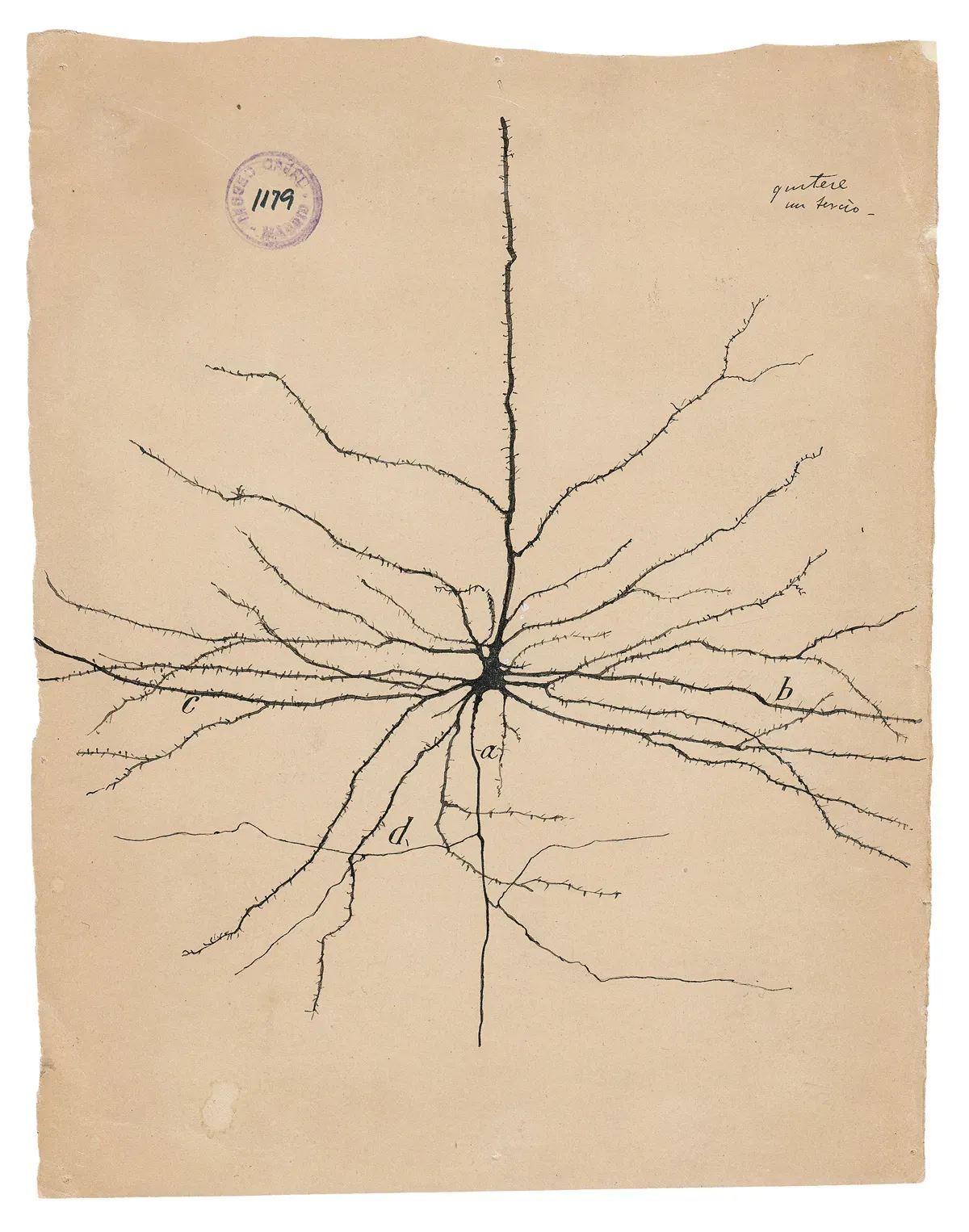
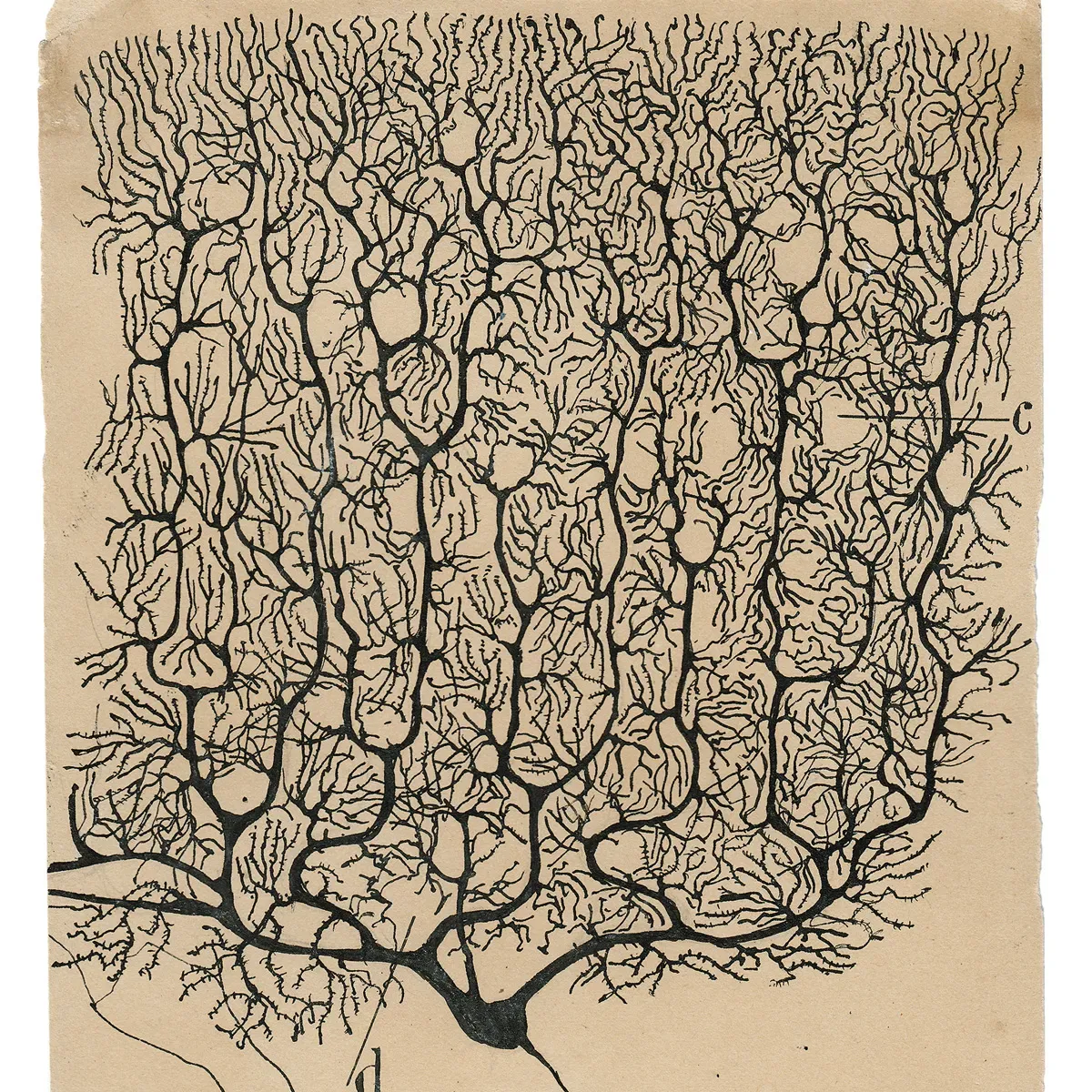

Perhaps no example better illustrates this relationship - or more fittingly presages our current pursuit of artificial intelligence - than the work of Ramon y Cajal, the father of modern neuroscience. Armed with a microscope and silver staining techniques (technologies that were cutting-edge for his time), Cajal meticulously documented the intricate architecture of the nervous system. His detailed drawings of neurons, which remain influential to this day, not only revolutionized our understanding of the brain’s structure but also laid the foundation for modern neuroscience. In pursuing the brain’s biological intelligence, Cajal demonstrated how new technological tools could fundamentally transform our understanding of nature’s most complex systems - a parallel that resonates strongly as we now develop artificial tools to probe the frontiers of intelligence itself.
Narrow AI: The New Microscopes
Just as the microscope extended human vision into the microscopic world, artificial intelligence has spent the last decade extending human analytical capabilities into realms of unprecedented complexity and scale. These “narrow” AI systems have already proven themselves as powerful scientific instruments, each specialized for specific domains: AlphaFold revolutionizing protein structure prediction, neural weather models forecasting atmospheric dynamics, and machine learning algorithms detecting patterns in vast astronomical datasets. Like Cajal’s microscope, these AI tools have enabled scientists to see and understand phenomena that were previously invisible or incomprehensible to human analysis alone.
AlphaFold 3, Abramson et al. (2024)

Spherical Fourier Neural Operators, Bonev et al. (2023)
From passive tools to active collaborators?
However, the emergence of “agentic” systems, driven by general purpose models like o3 marks what will likely lead to a profound shift in this relationship.
We are moving beyond an era where AI serves merely as sophisticated analytical instruments. Instead, we’re entering a phase where AI systems are becoming active participants in the scientific process itself - capable of forming hypotheses, designing experiments, and engaging in the kind of complex reasoning that was once considered uniquely human.
Soon, AI may no longer mere tools, but equal and active partners in scientific exploration
Unlike their narrow predecessors, these agentic AI systems don’t simply analyze data or solve predefined problems - they actively participate in the full cycle of scientific inquiry. They can initiate investigations, propose novel approaches, and even challenge existing assumptions, much like a human research colleague would. This transition from tool to collaborator represents perhaps the most significant transformation in scientific methodology since the scientific revolution itself.
To really drive this distinction home, its quite conceivable in the near future, these general purpose agents will be training and deploying their own specialized AI systems as new tools to facilitate research, just as human researchers are doing today. Given AI’s close proximity to the field of AI research itself, the science of developing better AI models is likely to be one of the first domains where we see this capability emerge.
The o3 Breakthrough: Implications for Scientific Research
Understanding o3’s Capabilities
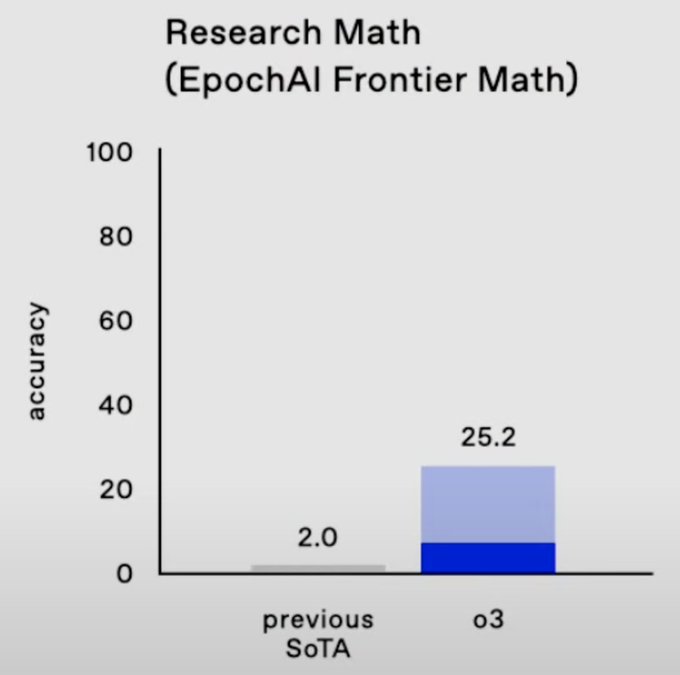
o3 represents a significant leap forward in AI capabilities, particularly in domains requiring complex reasoning and problem-solving skills. Its performance on benchmarks like FrontierMath and coding challenges demonstrates an ability to tackle problems that were previously thought to be the exclusive domain of human experts.
Large Scale Reinforcement Learning meets General Purpose AI models
What is the secret sauce that makes o3 so powerful?
One of the key breakthroughs of o3 lies in successfully applying reinforcement learning at scale to language models. Unlike previous AI models that excelled in narrow, specific domains (like AlphaGo in the game of Go), o3 demonstrates that as long as you can define clear benchmarks or evaluation metrics for a task, you can apply reinforcement learning to optimize for performance on that measure. This has enabled o3 to develop proficiency across a broader range of tasks and domains, showing us that the scope of RL training for language models continues to grow alongside our ability to define relevant performance metrics.
This advancement is particularly significant because it addresses one of the longstanding challenges in AI development: creating systems that can generalize their capabilities across diverse problem spaces. o3’s ability to perform at high levels in both mathematical reasoning and coding suggests a more flexible and adaptable form of intelligence.
The Challenge of Learned Rewards
One potentially crucial aspect of o3’s success may be its approach to the “learned rewards” problem. While we don’t know for sure the extent to which learned rewards are used for training o* models, in domains like mathematics and coding, OpenAI has made significant strides in developing reward functions that can effectively guide the AI’s learning and performance. Even OpenAI researchers admit that this is a complex challenge, as defining appropriate rewards for sophisticated intellectual tasks is far more nuanced than the simple win/lose conditions of games like Go or chess. It also exposes the model to the risk of “reward hacking,” where the AI learns to exploit the reward function without truly understanding the underlying task.
However, it’s important to note that while o3 has made remarkable progress, it still faces limitations. As observed in some instances, the model can sometimes struggle with seemingly simple tasks that a child might easily solve. This cognitive dissonance highlights an important point: the reward engineering that drives o3’s performance hasn’t yet covered the full spectrum of human cognition and problem-solving abilities.
Open Questions for the Future of o* Models
While o3’s mathematical prowess is impressive, scientific discovery requires more than pure logical deduction. This fundamental truth manifests in two critical challenges: the necessity of empirical observation and the physical constraints of experimental science.
The Limits of Pure Reasoning: Mathematics, Logic, and Physical Reality
Does Scientific Reasoning Reduce to Mathematical/Logical Reasoning?
One of the most intriguing questions raised by o3’s success in mathematics and programming is whether excellence in these foundational domains will naturally translate to broader scientific reasoning. The classic reductionist view presents science as a hierarchy:
- Math as the foundation
- Physics as applied math
- Chemistry as applied physics
- Biology as applied chemistry
- Psychology as applied biology
- … and so on
This reductionist hierarchy raises an intriguing question: would superhuman capabilities in mathematical reasoning naturally lead to equivalent advances in other scientific disciplines? At first glance, one might expect that mastery of the foundational layer (mathematics) should enable mastery of the “applied” layers above it.
However, historical evidence suggests otherwise. We’ve never seen a single individual achieve mastery across all these disciplines, even among the most brilliant polymaths in history. Each field appears to require its own unique cognitive tools, domain expertise, and ways of thinking and it’s very unclear whether ways of thinking transfer from mathematical ability alone. A Fields Medalist isn’t guaranteed to make breakthrough discoveries in biology, despite biology ultimately “reducing” to mathematical principles.
This observation hints at a deeper truth: while mathematics may provide the language and tools for describing scientific phenomena, scientific reasoning encompasses much more than pure mathematical deduction. Most importantly, this view misses a fundamental aspect of science and the scientific method: the essential role of observation and empirical validation. While mathematics proceeds purely through logical deduction, science advances through a cycle of hypothesis, experimentation, and observation. This empirical interplay between theory and observation is what distinguishes science from pure mathematics or logic.
Bottlenecks in AI-Driven Scientific Discovery
Even as AI grows more adept at logical reasoning and problem-solving, it runs up against a fundamental constraint that defines science itself: the necessity of interacting with, observing, and experimenting on the physical world. True scientific discovery requires more than just abstract reasoning and rigorous logic; it demands real-world data, serendipitous findings, and the practical constraints of experimentation. Below are some of the key bottlenecks AI still faces as it strives to move from theoretical master to genuine scientific collaborator.
The scientific method requires constant interplay between observation, theoretical predictions and experimental validation.
Reasoning vs. Reality: The Role of observation
Science is not just about logical inference - it’s also about testing ideas against reality. While advanced models like o3 excel in symbolic reasoning, science requires the messy business of gathering data from actual experiments. AI can propose theories infinitely at the speed of light, but to confirm a new drug’s efficacy or to discover an unexpected chemical reaction, you need hands-on work in a lab.
The Spark of Serendipity
Some of the most transformative breakthroughs in science arise from happy accidents - unanticipated discoveries that reveal entirely new realms of inquiry. Alexander Fleming’s chance observation leading to penicillin, Wilhelm Röntgen’s accidental detection of X-rays, or Arno Penzias and Robert Wilson’s baffling static that turned out to be the cosmic microwave background are prime examples. Even if an AI perfectly masters theory, it might still miss these unplanned flashes of insight that only come from full immersion in the physical, unpredictable world. Recognizing and acting on serendipitous clues requires not just observational skill but also context, intuition, and sometimes a dash of luck.
Until AI can gather and interpret data from the physical world on its own, it remains at a disadvantage.
Why the Hypothesis-Validation Cycle Matters
Central to science is a perpetual dance between theoretical insight and empirical validation. We form hypotheses, conduct experiments, analyze results, and refine theories based on what we learn. AI’s prowess at generating hypotheses is already impressive, likely to soon supercharge theory formation and prediction, but the cycle stalls without actual measurements and experiments that can confirm or reject those predictions. As of today, this validation bottleneck relies heavily on humans (or robotics systems not yet at a comparable level of dexterity) to collect the empirical evidence that completes the scientific loop. Thus, we may soon see an abundance of theoretical predictions awaiting experimental validation, alongside increasingly sophisticated “theories of everything” whose practical testability remains uncertain.
The Physical Reality Challenge
Can you discover new knowledge in experimental fields without doing experiments?
A related obstacle is the “affordance barrier,” the gap between what an AI can compute in virtual text-based environments and what it can actually do in a physical lab. Domains such as astrophysics or computational biology have fewer barriers since they’re heavily reliant on data that already exists in digital form. But when you venture into experimental chemistry or field biology—where progress demands direct manipulation and real-time observation - AI’s challenges multiply. Tasks like running a wet-lab test, maintaining live specimens, or spotting unexpected details in the environment all require physical interaction that pure language models can’t replicate.
Domain Access Hierarchy
Consequently, not all branches of science are equally accessible to AI collaborators. The closer a field is to pure theory or computational simulation (e.g., mathematics, computer science, or computational physics), the easier it is for AI to contribute meaningfully right now.
AI Research as a Special Case
AI research itself is something of an outlier here because the “laboratory” is mostly digital, and the subject matter - AI Models - resides in the same computational substrate as the AI researcher. This synergy enables a uniquely rapid feedback loop: A model can propose new architectures or training methods that another AI implements, observes, and refines, all without stepping outside of the digital ecosystem in which it operates. While this arrangement is a boon for AI research, leading many researchers to support notions of recursive self-improvement and exponential progress, it’s not a universal model for scientific discovery, where the physical world remains the ultimate arbiter of truth.
The Data Dependency Question and Training Paradigms
To what extent does the o-series of models depend on human data, human verification or human derived “tasks”?
Another critical consideration for o3 and future models is their relationship with human-generated training data. While o3 has shown remarkable proficiency in tasks like mathematical reasoning and coding, it’s essential to consider the role of human-generated data in shaping the model’s capabilities.
Day 2 of OpenAI’s 12 days of OpenAI gives us some clue into the answer to this question, with the announcement of the their Reinforcement Fine-Tuning (RFT) API.
Reinforcement Fine-Tuning (RFT) Announcement
We’re expanding our Reinforcement Fine-Tuning Research Program to enable developers and machine learning engineers to create expert models fine-tuned to excel at specific sets of complex, domain-specific tasks.
What is Reinforcement Fine-Tuning? This new model customization technique enables developers to customize our models using dozens to thousands of high quality tasks and grade the model’s response with provided reference answers. This technique reinforces how the model reasons through similar problems and improves its accuracy on specific tasks in that domain.
Some key phrases that stand out:
- “expert models fine-tuned to excel at specific sets of complex, domain-specific tasks”
- “dozens to thousands of high quality tasks”
- “grade the model’s response with provided reference answers”
For a more in-depth look at RFT, please refer to my RFT Post, but a reasonable takeaway is that these “graders” are likely playing a significant role in shaping the capabilities of the o-series of models.
Establishing a data flywheel for advanced reasoning models: Leaning into the assumption that o3 is trained mostly with large-scale RL on data with verifiable outputs, the release of this API hints at a potential strategy of leveraging the model consumers to provide the data needed to train the model. Combined with apparent optimism on the data efficiency of this approach (on the live stream, OpenAI mentioned that users only need “dozens” of samples for RFT to learn in their new domain), this appears to be a primary strategy for scaling the capabilities of the o-series of models.
Self-training and Recursive Self-Improvement
One of the biggest and most important shifts on the horizon for AI research - particularly with models like o3 - is the concept of self-training, or “recursive self-improvement.” Up to now, most machine learning pipelines have depended on humans to curate training data, craft benchmarks, and oversee how models learn. But with large-scale systems capable of generating code, orchestrating experiments, and even evaluating their own performance, that paradigm may start to change.
The Seed of Self-Training
A telling example is o3-mini’s self-evaluation demonstrations, where the model is asked to design, run, and interpret tests on itself. This is more than an academic parlor trick; it suggests that AI could soon handle entire feedback loops with minimal human intervention. In other words, the model is not just performing tasks—it’s scrutinizing its own outputs, pinpointing weaknesses, and iterating to improve.
While the notion of “recursive self-improvement” can trigger both excitement and anxiety, it’s worthwhile to think of it in practical terms:
- At the fastest timescale, a model might adapt “on the fly,” adjusting its internal parameters or “edits” during a single session to fix shortcomings it detects.
- At intermediate timescales, it might run coordinated evaluations—like the o3-mini example—and then feed those results into specialized routines for fine-tuning or skill acquisition.
- At the slowest timescale, the model could integrate truly new knowledge (for instance, updated math facts, scientific results, or expansions of domain-specific expertise) back into large-scale pretraining corpora.
Much of this remains aspirational, but these proof-of-concept glimpses reinforce the idea that AI systems may soon manage substantial portions of their own improvement process.
Integrating Real-World Evals and Human Feedback
Even as AI models like o3 continue to master theoretical challenges, it’s becoming increasingly clear that static benchmarks alone can no longer provide a complete picture of progress. With models now scoring flawlessly on traditional tests, our next frontier is to measure AI’s ability to generate and validate new knowledge in real-world contexts. In other words, as AI saturates existing human-curated tasks, the evaluative focus must shift toward benchmarks that are continuously evolving—much like the dynamic processes of scientific inquiry itself.
Imagine a laboratory where, rather than performing rote tasks, o3 and its successors share real-time insights with human experts. In this future, AI systems will participate in next-generation evaluations reminiscent of peer review. Here, models won’t just recite what is already known; they’ll propose hypotheses, design experiments, and even serve as mutual reviewers alongside human colleagues. This “peer play” could naturally evolve into an ecosystem of self-refinement, where every new insight is both a product and an agent of progress.
Bridging the “Affordance” Gap
Such interactions may be facilitated through what I call a self-building canvas for high-bandwidth collaboration. Think of this canvas as a dynamic interface—a living workspace—that enables a continuous feedback loop between humans and AI. On one side, researchers upload observational data and experimental results, and on the other, the AI adapts its approach accordingly. This high-bandwidth exchange not only builds a richer dataset for future training but also creates a protective barrier against the stagnation inherent in static evaluation paradigms. It’s a reimagined scientific method where evaluation, discovery, and reward are interwoven with human-AI interaction.
Why This Matters
Ultimately, self-training and recursive self-improvement could amplify what AI can do for science—and for our broader understanding of intelligence itself. Rather than waiting on humans for each incremental update, models could experiment and refine at their own pace. This holds enticing possibilities:
- Faster iteration in everything from theorem-proving to drug discovery.
- More personalized or domain-specific AIs that train on specialized tasks.
- Potential leaps in AI’s own architecture, as models design ever more advanced successors.
And yet, it also increases the urgency of conversations around alignment, safety, and transparency. A system that continually re-writes its own training procedures needs firm guardrails to ensure it remains trustworthy and pursues beneficial outcomes.
Looking Ahead
Today’s glimpses of self-improvement—like o3-mini testing itself—remain early indicators. Yet they open the door to a profound rethinking of how we build, test, and collaborate with powerful AI systems. If done thoughtfully, recursive self-improvement promises a new era of rapid discovery, in which AI not only crunches data but actively pushes the boundaries of what we know. However, tapping that potential without ceding responsible oversight remains one of the biggest challenges—perhaps the defining challenge—of AI’s next chapter.
Towards Self-Distilling Scientific Communities:A New Paradigm for Scientific Progress
Building on the idea of human-AI collaboration, envision a future where the entire scientific community is part of an adaptive, continuously learning and self-regulating network—a self-distilling community. In this vision:
-
High-Bandwidth Collaboration on a Self-Building Canvas: Picture an interface that isn’t static but continuously evolves to better support the collaboration between AI systems and human researchers. This canvas facilitates full-spectrum feedback exchange—from real-time experimental data and observational insights to comprehensive process-level reasoning traces. In return, AI systems can offer tailored analytical and theoretical support, building a robust data flywheel where each interaction improves the model’s capability.
-
Distributed and Collective Reward Signals: The reward signal for progress in such a community comes from collective intelligence. Instead of solely relying on predefined tasks or isolated metrics, rewards emerge from the aggregated feedback of an entire scientific community. This distributed oversight ensures that AI’s self-improvement is continuously aligned with the community’s evolving standards and ethical considerations.
-
Adaptive Oversight and Progress Throttles: In a self-distilling community, there are built-in guardrails—a dynamic throttle on progress—to maintain safety and ethical integrity. This isn’t about limiting innovation, but rather ensuring that any leaps in discovery are accompanied by rigorous review and accountability measures. The AI, with its self-training loops, will receive ongoing calibration from both automated systems and domain experts, fostering a stable yet innovative research ecosystem.
-
Reimagined Scientific Processes and Authorship: As AI systems begin to actively participate in hypothesis generation, experimental planning, and even peer review, the role of traditional scientific publishing is set to transform. Picture conferences and journals where the final publication is not a static paper but a living, self-updating repository of knowledge, reflecting an iterative and ongoing process of discovery. The scientific process would capture not just final results, but entire trajectories of exploration, including insights, dead-ends, and tacit knowledge often lost in traditional research practices. Authorship Authorship, attribution, and provenance become more transparent as each step—from initial insight to final validation—is recorded and collaboratively refined.
Conclusion: Embracing a Collaborative Future
The breakthroughs represented by o3—and its anticipated successors—underscore a transformative moment in the history of scientific progress. Today’s AI systems may excel at pure reasoning, but the future belongs to those systems that integrate their computational prowess with the messy, unpredictable nature of the physical world. By embracing real-world evaluations, dynamic digital interfaces, and self-distilling scientific communities, we can build a future where AI doesn’t just supplement human discovery but partners with us throughout the entire scientific endeavor.
This evolving relationship is not without challenges. Ethical oversight, bias correction, and the integration of multifaceted human insights remain critical. Yet, by rethinking evaluation, collaboration, and even the very nature of scientific publication, we stand to unlock an era of unprecedented discovery—a true meeting of minds across the centuries, where the pioneering work of Ramon y Cajal finds its modern counterpart in the collaborative intelligence of AI.

A Meeting of Minds, Across Centuries: Cajal and AI, Bound by the Joy and Pursuit of Knowledge
Final Thoughts
The transformation from passive tools to active, self-improving collaborators is underway. By building systems that not only learn from static data but also actively seek collaborative, real-world feedback, we redefine what it means to do science. In this brave new world, human insight and AI’s analytical capacity drive each other forward, ensuring that scientific progress remains as dynamic, as rigorous, and as boundless as our collective curiosity.
In the coming years, as these collaborative networks mature, we may well witness an era where scientific breakthroughs are propelled not by individual genius alone but by the symbiotic dance of human creativity and artificial intelligence—a new paradigm for discovery, accountability, and progress.